Find a suitable model for long-term efficiency gains.
Senior Design · Wabtec rail efficiency study
AI Drivetrain Efficiency
Machine learning for smarter locomotive motor power distribution.
Michael Penfield · Joel Sander · Connor Pflugh · Jacob Harsch


Introduction
Wabtec builds and maintains locomotives that run in demanding environments.
- Global rail equipment, systems, and digital solutions provider.
- High-performance locomotives operate around the clock.
- Sustainability gains matter when multiplied across fleets.

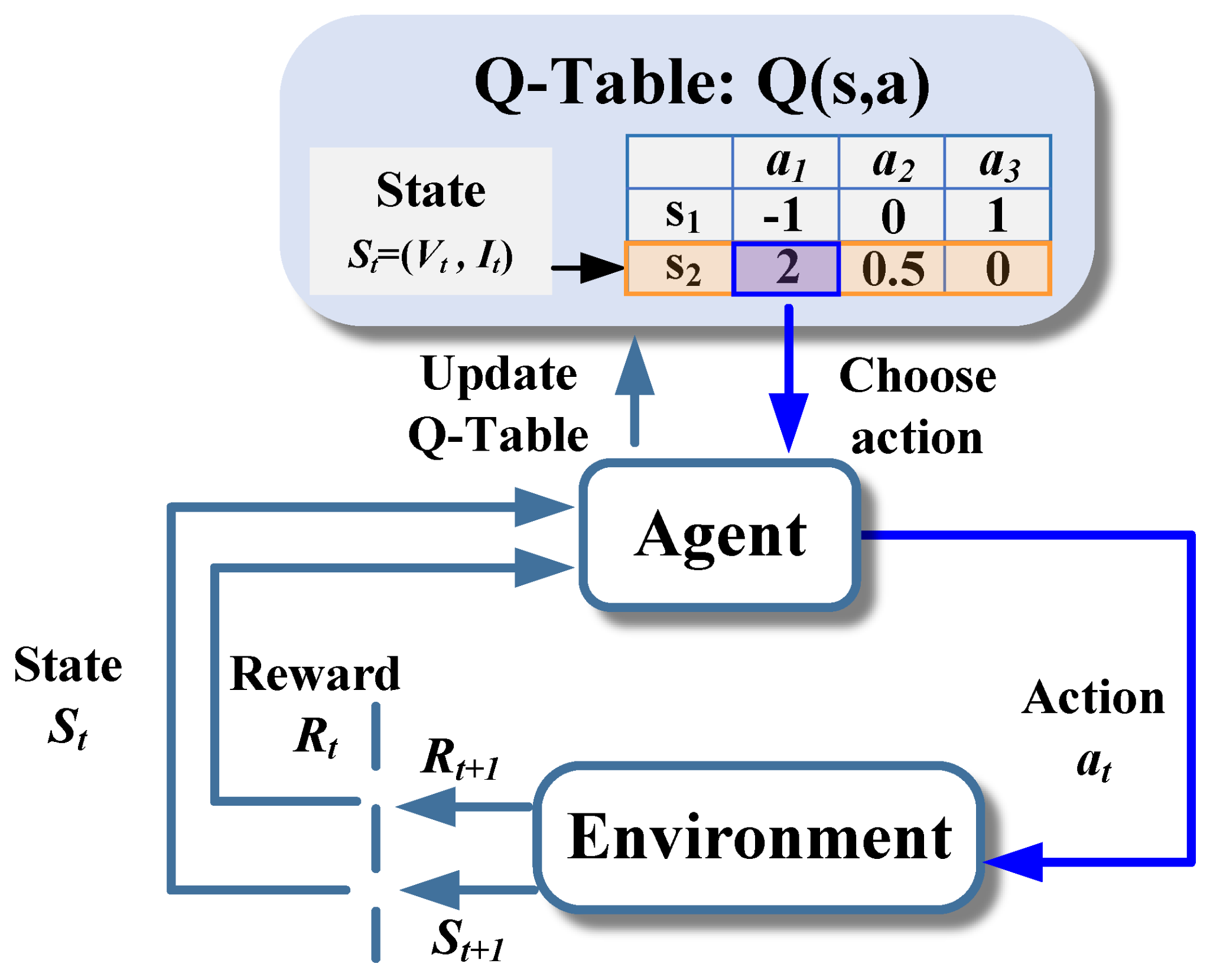
State-Based Candidates
Q-Table and SARSA make discrete policy jumps.
- Q-Table remembers best actions for known states.
- SARSA behaves more conservatively.
- Both struggle when smooth control is needed.
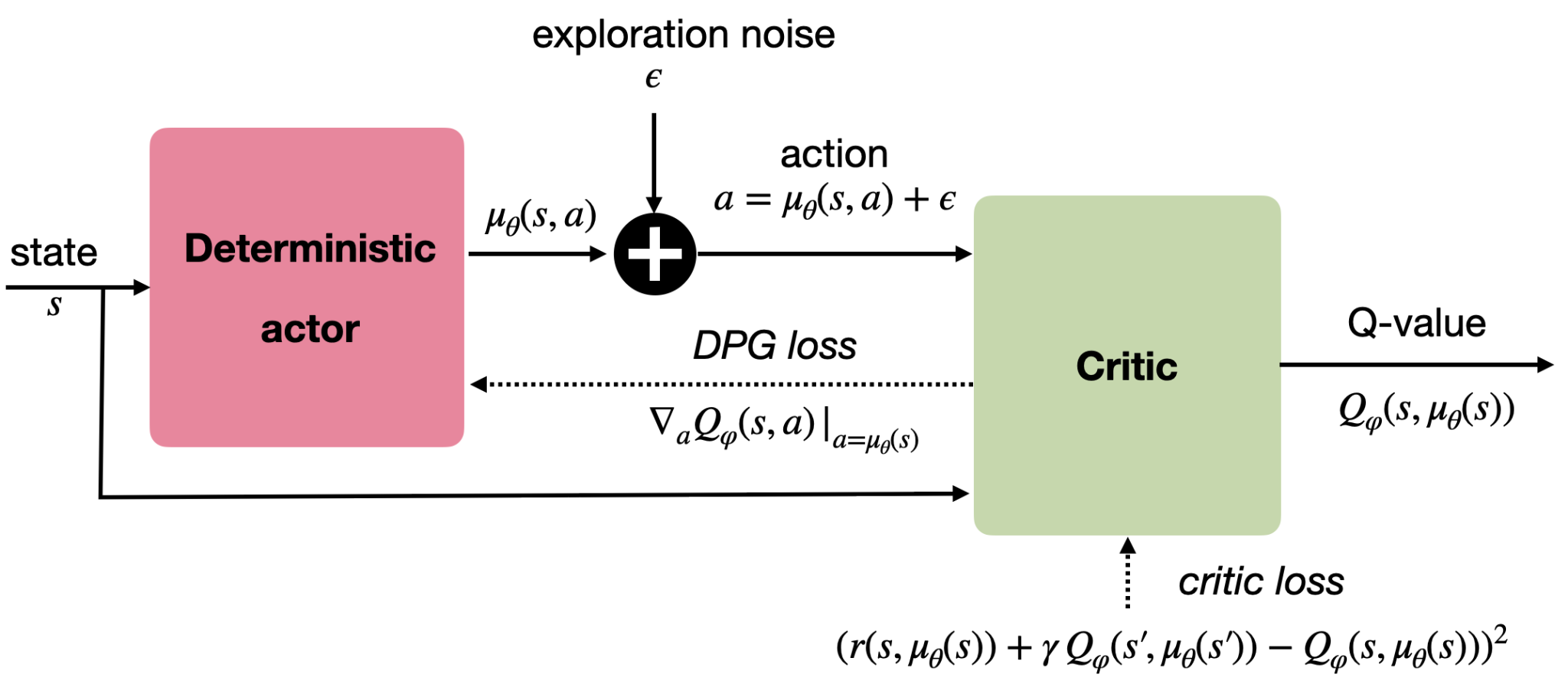
Continuous Candidates
DDPG and TD3 treat power allocation like dimmer switches.
- Actor chooses the power setting.
- Critic evaluates the choice.
- TD3 adds a second critic for stability.
Supervised Learning Check
MLP tested whether reinforcement learning was the right paradigm.
Labels were generated from the simulation equations using KKT optimization.
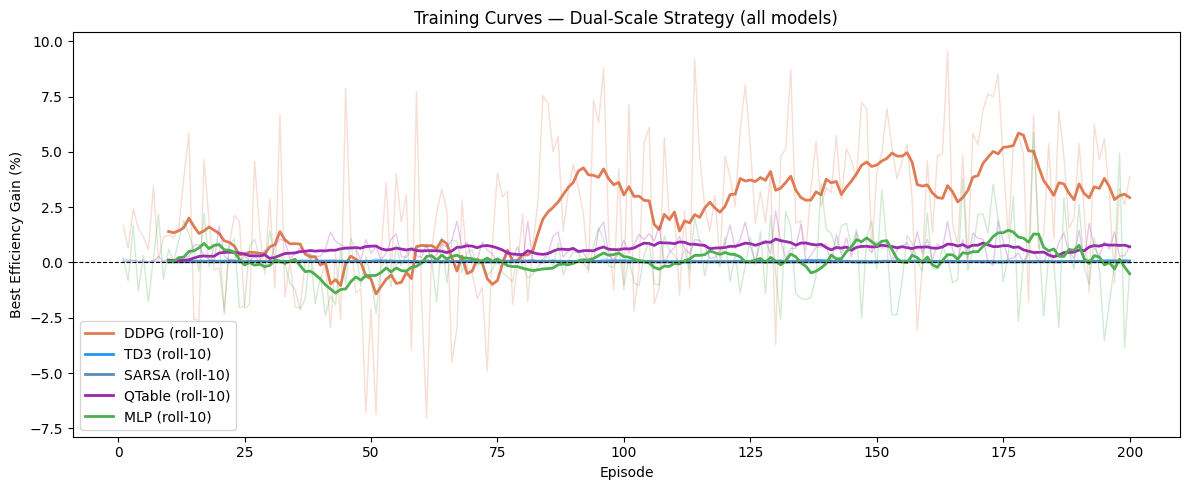
Best Performance Model
DDPG generalized after roughly 75 training episodes.
The orange line showed stronger gains, though variance suggests more training would help consistency.
Result Validation
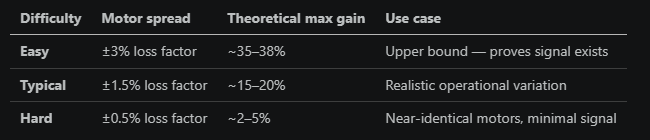
Models were tested against new difficulty levels.
Each difficulty scales motor inefficiency to create easier or harder validation sets.
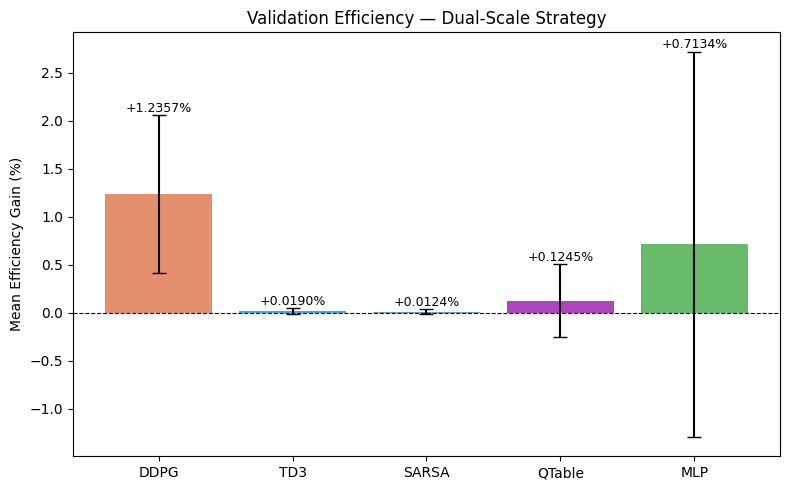
Final Results · Validation
DDPG consistently achieved the strongest validation results.
- Some models failed to converge.
- Others had too much variance.
- DDPG scaled across easy, medium, and hard cases.